
Motivation
"Another tutorial on linear regression?!" Someone exclaims. Before I start, I feel the need to clarify what this blog is and is not about. After all, there are probably hundreds if not thousands of tutorials, articles, and online courses on this topic.
But first, let me motivate this topic a little using a quote from text Mathematics for Machine Learning.
"Regression is a fundamental problem in machine learning, and regression problems appear in a diverse range of research areas and applications, including time-series analysis (e.g., system identification), control and robotics (e.g., reinforcement learning, forward/inverse model learning), optimization (e.g., line searches, global optimization), and deep learning applications (e.g., computer games, speech-to-text translation, image recognition, automatic video annotation). Regression is also a key ingredient of classification algorithms." -- Deisenroth, M. P., Faisal, A. A.,, Ong, C. S. (2020). Mathematics for Machine Learning. Cambridge University Press.
Interestingly, because of its ubiquitous influence in many fields (ML, stats, optimization, control theory, etc.), I found that the notations and solutions to this problem can be inconsistent and sometimes even convoluted1 2 3.
This is where this post comes in. It’s meant to provide a holistic view on different ways to formulate linear regression problem from the perspectives of machine learning, statistics & probability, and optimization. In this post, we'll introduce linear regression as the most fundamental regression problem. And on top of that, I'll summarize all the different notations and problem formulations I’ve seen so far.
What it is not about: This post is not a step-by-step tutorial to introduce any specific linear regression concept from stretch.
In this post, I assume that readers don’t have specialized knowledge in ML. If you do, feel free to skip any section that is less relevant for you.
Notation Convention
Notations: There are simply too many notations floating around in machine learning space so in this blog we will stick with using inputs (aka features) denoted by or (data matrix), output (aka prediction, hypothesis) denoted by , weights (aka parameters) denoted by or , bias (aka error) denoted by . For more details about different notations please refer to "Miscellaneous: notations" section at the end.
Other notation:
- number of training examples
- number of inputs not including bias
- inputs (features) of training example (i.e. a vector)
- value of input (feature) in training example (i.e. a scalar)
What's linear regression?
My first contact with linear regression dates back to 2020, when I took Andrew Ng’s Machine Learning course on Coursera. Simply put, linear regression is an approach to finding a linear equation (model) that takes in one or more inputs and outputs a continuous output variable (target variable).
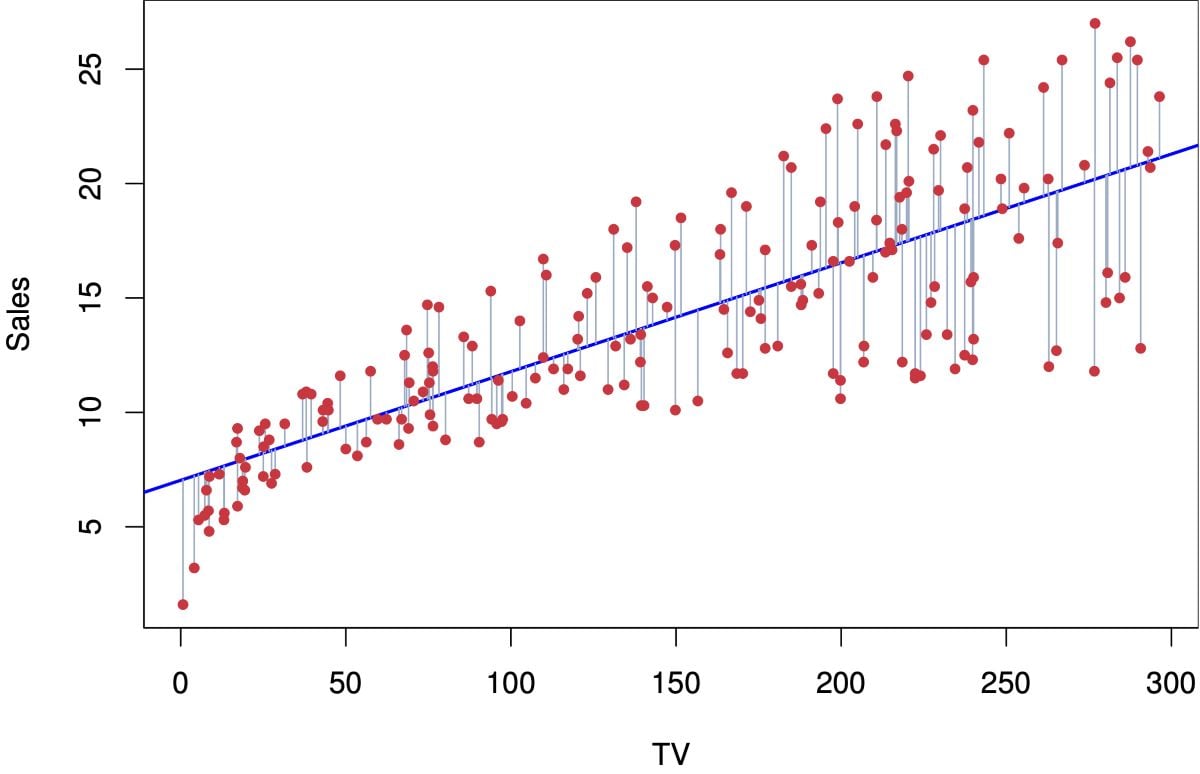
An example could be predicting sales (output variable) based on TV’s advertising budget (input variable). From the graph below, red dots represent the historic data; the blue line is that linear equation (our model) that we magically found, which outputs the best predictions for both training & testing data (aka "generalize well").
How do we use the model? Now if I want to predict sales with a TV advertising budget of 200 units using this model, I can trace my finder up from the 200 tick on the x-axis until it meets the blue line (i.e., our model), then trace it to the left until it touches the y-axis. The exercise would give you a prediction about 16–17 units of sales.
Math
We can write out this linear equation (blue line) in a mathematic form:
where is the output variable, our predicted height, and is our input, weight.
A more general format to write it in case we're dealing with multiple inputs (multi-variate linear regression) is:
where , (data matrix), , . Note that here we let all for every row in to complete the data matrix so that we can include bias as a weight ().
How to fit a LR model?
Each formulation will be discussed in two parts:
- high-level intuition
- some math behind it
I won't go too deep into the math here as you can find lots of other articles and textbook reference on math. If you'd like, you can totally skip the math part and still understand each formulation pretty well.
Formulation 1: Gradient descent ("the ML way")
Intuition
Gradient descent is probably the most popular opitimization algorithm right now in the machine learning space, as it’s fundamental to training not only classic ML models but also all deep neural networks that require backpropagation.
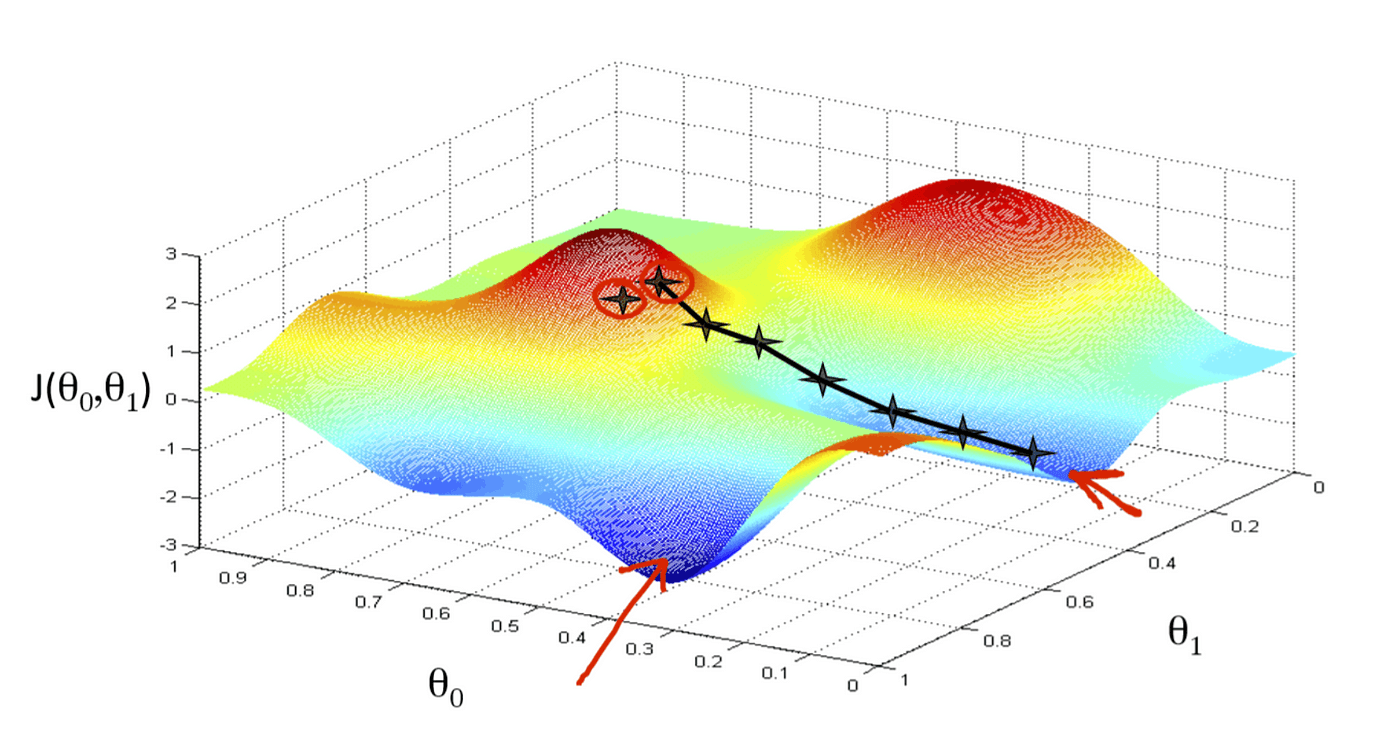
The goal here is to minimize the cost function in high-dimensional space by iteratively taking "small steps" in the direction with a lower cost. One analogy in the 3D world could be descending a mountain from its peak; here, the altitude will be your cost function’s output . How many weights are you optimizing then? You probably would have guessed—it’s your latitude and longitude ( and below!). Here’s a visual to help you imagine.
What if we have more than two inputs (features) in our dataset? The math is the same: simply take the partial derivative w.r.t. the weight of each input variable from where n is the number of input variables.
A high-level summary of the steps takes in gradient descent is described below:
- Define a cost function (e.g. mean squared error (MSE), mean absolute error (MAE), etc.)
- Minimize using gradient descent technique until the change of between iteration and converge within a bound
- Take a step towards the opposite direction of the gradient of cost function
- Adjust
- Take another step
- Repeat until convergence
Math
Step 1: Define a MSE cost function
Step 2: Take the gradient w.r.t each and update simultaneously through vectorization
Step 3: Compute loss and if then repeat step 2 until converge.
Formulation 2: The Normal equation
Intuition
Whenever we approach a mathematical problem, in this case, minimizing our chosen cost function, there are usually two types of solutions: analytical solutions and numerical solutions.
Analytical solutions have a strict logic and return an exact answer; for example, factorizing a matrix using singular value decomposition or other linear algebra methods based on the properties of the matrix.
Unfortunately, there are many problems that do not have an exact solution, such as the travelling salesman problem. A numerical solution makes reasonable guesses and eventually returns a "good enough" solution that meets certain constraints. Gradient descent gives us a numerical solution of weights because it’s nearly impossible to reach the global minimum once you find yourself optimizing a non-convex cost function in a high-dimensional space like neural networks. Machine Learning Mastery gives a more detailed illustration of the differences.
Normal equation is a analytical solution to find exact using data matrix and ground truth .
Math
Recall previously we're able to write in matrix notation:
Then we can substitute the above expression into the cost function to rewrite the sum as matrix notation as well:
denotes the Euclidean norm of a vector defined as , which is equivalent to the expression! Now expand the Euclidean norm using matrix transpose identities you will get:
Note that is a vector, and so is . So when we multiply one by another, the order does not matter (i.e. ). Further simplify the expression into:
To find our unknown , we will derive by and compare to zero. Deriving by a vector involves matrix caculus but in the end we just derive by each component of the vector, and then combine the resulting derivatives into a vector again. Eli Bendersky has a wonderfun blog explaining how to derive matrix notation if you're interested. The result is:
Now, assuming that the matrix is invertible, we can multiply both sides by and get:
This is the normal equation.
Formulation 3: Minimum likelihood estimation (MLE)
In additional to the first two common ways to look at linear regression, we can take a probablistic approach to formulate the problem and by the end you will see they have very similar steps.
Intuition
Let's say we get some training examples (i..e our training dataset) and fit a linear regression model (curve fitting) that models these training examples. We assume there's a function that maps inputs to corresponding funciton values . The ground truths can then be expressed as , where is an i.i.d random variable that describes observation noise, which we have no control of.
The goal is to infer the function that generated the training data and generalizes well to new input data. Since we're dealing parametric models, a parametric estimation method like MLE or MAP can be applied to estimate the best parameters given certain data.
Note: is just the bias in formulation 1 and 2 but we choose different notation here to stick with probabilistic convention.
Math
The mathematical expression of the model is given by
Assuming the noise has a Gaussian underlying distribution and we know its variance for the time being. We obtain the maximum likelihood parameters as
To find the optimal parameters, we then minimize the negative log-likelihood
There you go! So the likelihood function is just as same as the cost function in method 2 with different names. The rest is the same - take derivative of w.r.t the parameters and equalize it to zero and solve for the optimal parameters. And you probably guessed it, the result is just normal equation. However, the amazing part is we started from a very different formulation.
Formulation 4: Maximum a-priori estimation (MAP)
Intuition
MLE and the normal equation are both prone to over-fitting due to its closed-form nature, which means they will fit a curve as perfect as possible given training data. This approach usually won't generalize to testing data and in reality could be computationally costly to compute the inverse of a matrix.
This is where MAP estimation comes in. We can place a prior distribution on the weights. Once a dataset , is available, instead of maximizing the likelihood we seek parameters that maximize the posterior distribution to find the optimal parameters.
Math
The posterior over the parameters , given the training data , is obtained by applying Bayes' theorem and then followed by a log-transform as
where the constant comprises the terms that are independent of . The MAP estimate will be a “compromise” between the prior (our suggestion for plausible parameter values before observing data) and the data-dependent likelihood.
To find the MAP estimate , we minimize the negative log-posterior distribution with respect to , i.e., we solve
Formulation 5: Least squares problem
Intuition
Another way to look at a regression problem is to realize that it's a subset of least squares problem. Imagine that we have a matrix of size (i.e. more training examples than number of features), then usually does not have a solution. This is called an overdetermined case in least squares problem where we can't find a perfect solution so instead we seek the least squares solution.
Math
We then try to find set of parameters that minimizes the sum of squares of the error
the solution of optimal parameters is
Again, you will find we arrive at the same answer solved in formulation 2 and 3. This tutorial created by Alex Townsend from MIT does an amazing job at explaining how we can get from least squares problem to normal equation.
Miscellaneous: notations
| Convention used in this blog | Other Notations |
|---|---|
| output variable | prediction, hypothesis (function) |
| input variable | predictor, regressor, independent variable, observation / data matrix, feature matrix |
| ground truth | response, label, dependent variable, target variable |
| cost function | loss function, error function, , objective function |
| bias | error , observation noise |
| weight | parameter , coefficient |
| learning rate | - |
Acknowledgement
Thanks to Ian Webster for reviewing and making this post better.